SFTP オフラインデータ取り込み
概要
本ドキュメントでは、オフラインデータ取り込みにおける SFTP ディレクトリ構成、ファイル形式、メタデータ要件、設定手順、およびコマンドごとの動作仕様について定義します。本資料は、取り込みファイルを一貫した方法で準備、アップロード、および検証するためのリファレンスとして使用されます。これらのガイドラインにより、取り込みワークフロー全体での信頼性の高い処理、エラーハンドリング、およびトレーサビリティを確保します。
本仕様は、以下の取り込みタイプに適用されます:
-
UPSBATCH: ユーザープロファイルおよびセグメントの取り込み
-
UPSLINK: ユーザーIDのリンク(ユーザー識別情報の紐付け)
-
HIVEUPLOAD: Hive テーブルのアップロード
SFTP ディレクトリ構成
すべての取り込みファイルは、設定された SFTP ベースパス(ftpBasePath)にアップロードする必要があります。ディレクトリ構成は取り込みタイプごとに分離されており、アップロードから処理、アーカイブまでのファイルライフサイクルを明確に管理できるよう設計されています。
ディレクトリ構成
/
└── offline_data/ (ftpBasePath – 設定可能)
├── upsbatch/ UPS バッチ取り込み
├── upslink/ ユーザーリンク取り込み
├── hiveupload/ Hive テーブルアップロード
└── archive/
├── processing/ 一時処理領域
│ ├── upsbatch/
│ ├── upslink/
│ └── hiveupload/
├── processed/ 正常処理済みファイル
│ └── YYYYMMDDHHMMSS/
│ ├── upsbatch/
│ ├── upslink/
│ └── hiveupload/
└── failed/ エラーログ付き失敗ファイル
└── YYYYMMDDHHMMSS/
├── upsbatch/
├── upslink/
└── hiveupload/
タイムスタンプ付きディレクトリにより、トレーサビリティおよび監査性が確保されます。失敗したファイルは、対応する .error ログとともに保存され、処理失敗の詳細情報が記録されます。これにより、デバッグや再処理を容易に行うことができます。
サポートされている圧縮ファイル形式
本セクションでは、取り込みファイルのアップロードに使用可能なアーカイブ形式を定義します。サポート対象の形式を限定することで、取り込みパイプラインとの互換性を確保し、未対応の圧縮形式による処理エラーを防止します。
設定項目:
sftp.allowed.archive.extensions
デフォルトでサポートされる形式:
-
.zip: 標準 ZIP 圧縮形式
-
.tar.gz: GZIP 圧縮を使用した TAR アーカイブ
SFTP 取り込みレイヤーでは、上記形式のみ受け付けます。
サポートされているデータファイル形式(アーカイブ内)
本セクションでは、圧縮アーカイブ内に含めることができるデータファイル形式を定義します。これらの形式は、構造化データおよび半構造化データを効率的に取り込むことを目的として選定されています。
設定項目:
sftp.allowed.file.extensions
デフォルトでサポートされる形式:
-
.csv: カンマ区切り、またはカスタム区切り形式
-
.txt: プレーンテキスト形式
-
.json: JSON 形式(バッチデータの場合は JSON Lines 形式)
ファイル命名規則
ファイル名に厳密な制約はありません。これにより、さまざまなデータ提供元やワークフローに柔軟に対応できます。ただし、ファイルの識別および追跡を容易にするため、意味のある一貫した命名を推奨します。有効な拡張子であれば、任意のファイル名を使用できます。
例:
-
segments_20240115.zip
-
user_linking_grouped_20240115.tar.gz
-
products_hive_upload.zip
圧縮ファイルの内容要件
各圧縮ファイルには、適切な処理を行うためにメタデータファイルおよびデータファイルの両方を含める必要があります。メタデータファイルは取り込み方法を定義し、データファイルには実際に処理されるレコードが含まれます。
各圧縮ファイルに必須の内容:
-
メタデータファイル(必須)
以下のいずれか1つを必ず含めてください(複数不可):
-
metadata.json
-
metadata.properties
-
metadata.txt
-
-
データファイル(必須)
-
サポート対象拡張子(.csv、.txt、.json)のファイルを1つ以上含めること
-
有効なメタデータファイルが含まれていないファイルは拒否されます。
SFTP 認証情報およびサイトマッピングの設定
ダッシュボードでの認証情報設定
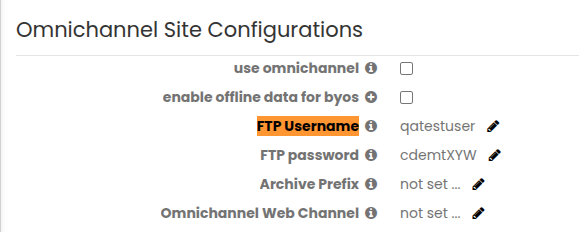
SFTP 認証情報は、Personalization Platform 内の Site Configuration RR で設定する必要があります。これらの認証情報は、ファイル取り込みのために SFTP サーバーへ安全に接続および認証するために使用されます。
Omnichannel Site Configurations 配下で、FTP Username および FTP Password を作成し、SFTP 接続を確立して取り込みファイルを処理します。
BuildFTP 設定の更新
ダッシュボードで認証情報を設定した後、BuildFTP の設定を更新し、各サイトを対応する SFTP パスへマッピングします。これにより、ファイルがサイトごとに正しくルーティングおよび処理されます。
config.properties に以下のエントリを追加または更新してください:
sftp.allowed.sites=<allowed_sites_list> sftp.ftp.base.paths.per.site=<site_id_1=path1;site_id_2=path2>
例
sftp.remote.server.host=ftp.richrelevance.com sftp.allowed.sites=801,1218 sftp.ftp.base.paths.per.site=801=/path/offline;1218=/userpath/batch
コマンド実行リファレンス
UPSBATCH コマンド仕様
UPSBATCH コマンドは、ユーザープロファイル、セグメント、および属性データの取り込みに使用されます。フルロードおよび増分ロードの両方をサポートし、カラムナーストレージなどのオプション最適化も利用可能です。
サポートされるオプション
| オプション | 必須 | デフォルト | 説明 |
|---|---|---|---|
| attribute | Yes | なし |
属性タイプ識別子を定義し、データの処理方法を決定します。一貫性を確保するため、厳格なバリデーションルールに従う必要があります。 使用可能文字: 英数字、アンダースコア(_)、ハイフン(-) バリデーションエラー:
例:
|
| loadtype | No | full |
既存データを全置換するか、増分更新として適用するかを指定します。取り込みユースケースに応じた柔軟な運用が可能です。 許可値:
delta 以外の値はすべて full として扱われます。 |
| columnarSupport | No | false |
特定条件を満たす場合に、サポート対象属性に対して最適化されたカラムナーストレージを有効化します。大規模データ処理におけるパフォーマンスを向上させます。 許可値: true, false 有効化条件:
columnarSupportが有効になっていない場合、loadtype=deltaを使用してアップロードされたセグメントは、既存のセグメントデータを上書きします。最新のファイルに存在するセグメントのみが保持されます。 columnarSupport=trueの場合、以前にアップロードされたセグメントは保持されます。後続のアップロードからの新しいセグメントは、既存のデータを置き換えるのではなく、追加されます。これにより、複数のアップロードにわたってセグメントが累積的に構築されます。 セグメントアップロードでcolumnarSupportを有効にするには、次のコマンドを使用します。 upsbatch <filename> -attribute rr-segments -columnarSupport true |
例
例 1: rr-segments フルロード(metadata.json)
ファイル構成
segments_full_20240115.zip ├── metadata.json [必須] └── segments_data.json [データファイル]
SFTP アップロードパス
/offline_data/upsbatch/segments_full_20240115.zip
metadata.json
{
"command": "upsbatch",
"attribute": "rr-segments",
"loadtype": "full"
}
注: メタデータファイルは .json または .properties のいずれかを使用できます。
例 2: rr-userattributes 増分ロード(metadata.properties)
ファイル構成
userattributes_delta_20240115.tar.gz ├── metadata.properties [必須] └── user_attributes.json [データファイル]
metadata.properties
command=upsbatch attribute=rr-userattributes loadtype=delta
例 3: wine-segments 増分ロード(metadata.json)
ファイル構成
wine_segments_delta_20240115.zip ├── metadata.json [必須] └── wine_segments.json [データファイル]
metadata.json
{
"command": "upsbatch",
"attribute": "wine-segments",
"loadtype": "delta"
}
UPSLINK コマンド仕様(ユーザーリンク)
UPSLINK は、複数の識別子を単一ユーザーに関連付けることでユーザーIDのリンクを処理します。データ量に応じて、リアルタイム処理およびバッチ処理の両方をサポートしています。
サポートされるオプション
| オプション | 必須 | デフォルト | 説明 |
|---|---|---|---|
| command | Yes | upslink |
コマンド識別子。 |
| linktype | No | explicit |
リンク処理方法を指定します。
不正値エラー: "unknown 'linktype' argument. Known values are: 'explicit' and 'grouped'" |
| loadtype | No | full |
既存リンクを全置換するか、増分更新するかを制御します。
delta 以外の値は full として扱われます。 |
データ形式
データは正しく解析されるよう、指定された区切り形式で提供する必要があります。各行は、リンクされたユーザーIDのグループを表します。
形式: Ctrl+A(\u0001)区切りの CSV
user1^Auser2^Auser3 user4^Auser5^Auser6
ルール:
-
1行あたり最低2ユーザー以上を含める必要があります。
-
ユーザー数が2未満の行は無視されます。
-
最初のユーザーがプライマリID、以降が代替ID(別識別子)として扱われます。
例
例 1: Explicit + Full リンク(デフォルト)
ファイル構成
user_linking_explicit_20240115.zip ├── metadata.json └── user_links.csv
アップロードパス
/offline_data/upslink/user_linking_explicit_20240115.zip
metadata.json
{
"command": "upslink"
}
例 2: Grouped + Full リンク(大規模処理向け)
ファイル構成
user_linking_grouped_20240115.tar.gz ├── metadata.properties └── user_links_grouped.csv
metadata.properties
command=upslink linktype=grouped
例 3: Grouped + Delta リンク(小規模ファイル向け)
ファイル構成
user_linking_grouped_delta_20240115.tar.gz ├── metadata.json └── user_links_delta.csv
metadata.json
{
"command": "upslink",
"linktype": "grouped",
"loadtype": "delta"
}
HIVEUPLOAD コマンド仕様
HIVEUPLOAD は、ファイルを Hive テーブルへ直接アップロードするために使用されます。ファイル名は柔軟に設定可能であり、メタデータ内で指定された情報に基づいて対象テーブルが決定されます。
メタデータマッピング
| FTP オプション | メタデータキー |
|---|---|
| site hiveupload | command=hiveupload |
| -table <tablename> | table= |
主なルール
以下のルールは、Hive 取り込み時の一貫した動作を確保し、テーブルマッピングの曖昧さを防ぐためのものです。
-
データファイル名はテーブル名と一致している必要はありません。
-
アーカイブ名は任意に設定できます。
-
テーブル名はメタデータ内でのみ定義します。
-
すべてのアップロードはデフォルトのマーチャントデータベースを使用します。
例
ファイル構成
userfavorites_upload_20240115.zip ├── metadata.json [必須] └── userfavorites.csv [データファイル]
アップロードパス
/offline_data/hiveupload/userfavorites_upload_20240115.zip
metadata.json
{
"command": "hiveupload",
"table": "userfavorites"
}
metadata.properties(同等設定)
command=hiveupload table=userfavorites
各アーカイブにつき、メタデータファイルは1つのみ必要です。